
Noisy Student Training in Vision and Speech Processing
Published:
Introduction
Many state-of-the-art (SOTA) models are trained with supervised learning which requires a large corpus of labeled data. However, by learning from only labeled data, we limit ourselves from making use of unlabeled one which is much more abundant. In this post, we will discuss a method called Noisy Student Training [1, 2] which is a semi-supervised learning method that can be used to train models with unlabeled data. We will also discuss how this method can be used to further improve the performance of SOTA models.
Related Works
Noisy Student is similar to knowledge distillation (KD) [3], which is a process of transferring knowledge from a large model (i.e., the teacher) to a smaller model (i.e., the student) while still retains most of the teacher’s performance. Unlike NST, KD does not add noise (e.g., data augmentation, model generalization) during training, and typically involves a smaller student model. In contrast, one can think of NST as the process of “knowledge expansion”. Another way of distillation is to apply NST twice: first to get a larger teacher model $T’$ and then to derive a smaller student $S$.
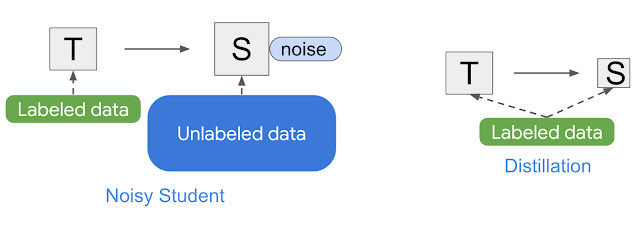
Noisy Training Student
Method
The NST algorithm assumes that we have a labeled dataset $L$, an unlabeled set $U$. In general, NST generates a series of models as follows:
- Train a teacher model $T_0$ on $L$ with noise. Set $T=T_0$
- Generate labeled dataset $T(U)$.
- Mix dataset $L$ and $T(U)$ to form a new labeled dataset. Use mixed dataset to train new model $T’$ with noise.
- Set $T=T’$ and go to step 2.
This algorithm is an improved version of self-training, and distillation. The key improvements lie in adding noise to the student model during training. The intuition behind this is that the teacher model will be more robust to noise and thus can be used to generate more accurate labels for the unlabeled data.
Noising Student
The authors of [1] propose two types of noise: input noise (i.e., data augmentation) and model noise. For input noise, there are multiple techniques applied to the input data, depending on the task (e.g., SpecAugment [4] for speech processing, flipping and cropping for image processing). For model noise, there can be dropout, stochastic depth [5], etc.
Other Techniques
NST also works better with some additional trick: data filtering and balancing, data mixing, gradient mask [8], and (in some cases) label smoothing [6], etc.
Filtering
Vision: we can filter images that the teacher model has low confidences on.
Speech: authors of [2] introduce a filtering score given as a function of teacher’s score $\mathcal S$ and the token length $\ell$ of a transcript generated. The normalized filtering score is defined to be
with parameters $\mu,\beta$ and $\sigma$ fit on generated set. $\mu,\beta$ are fit via linear regression on the value pairs $(\ell_i,\mathcal S_i)$ of the generated transcripts. $\sigma$ is obtained by computting the standard deviation of $(\mathcal S_i-\mu\ell_i-\beta)/\sqrt{\ell_i}$. These parameters are fit for each new generation of teacher models. Finally, with this score, we filter the transcripts with scores $s(\mathcal S,\ell) > s_{\textrm{cutoff}}$, with $s_{\textrm{cutoff}}$ is pre-defined.
Balancing
To ensure that the distribution of the unlabeled data is match that of the training set, we also need to balance the number of unlabeled data for each class.
Vision: We duplicate images in classes where there are not enough images. For classes where there are too many images, we select the images with the highest confidence.
Speech: We use sub-modular sampling [7] to balance the dataset to a desired distribution.
Notes: the benefits of data balancing can be significant for small models while less significant for larger models.
Results
NST can improve the performance of previous SOTA models on ImageNet by 2.0% (top-1). On robustness test sets, it improves ImageNet-A top-1 accuracy from 61.0% to 83.7%, reduces ImageNet-C mean corruption error from 45.7 to 28.3, and reduces ImageNet-P mean flip rate from 27.9 to 12.2.
In speech recognition, this method can achieve 4.2%/8.6% word error rate (WER) by only using the clean 100h training set, and 1.7%/3.7% WER by using the unlab-60k subset of LibriLight as the unlabeled set for LibriSpeech 960h, on the clean/noisy LibriSpeech test sets. These results improve the previous SOTA by 1.1%/2.1% and 0.5%/1.1% WER, respectively.
In VLSP 2022 competition, by adapting NST, we can achieve 10.04% WER on the given test set, placing us at 2nd place in the competition. More about our approach can be found in this paper.
References
[1] Self-training with Noisy Student improves ImageNet classification
[2] Improved Noisy Student Training for Automatic Speech Recognition
[3] Distilling the Knowledge in a Neural Network
[4] SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition
[5] Deep Networks with Stochastic Depth
[6] Rethinking the Inception Architecture for Computer Vision
[7] A Submodular Optimization Approach to Sentence Set Selection
[8] Improving Pseudo-label Training for End-to-end Speech Recognition Using Gradient Mask